301 Redirects with Static Sites
Table of Contents
- Why did I want to set up redirects?
- 1. Rename the source code repository
- 2. Update where the project name is hard-coded
- 3. Update the domain in GitHub Pages settings
- 4. Change redirects from the old domain to the new domain
- 5. Set up SEO trackers to monitor the new domain
- 6, 7, and 8. Wait, turn off redirects, and retire the old domain
Why did I want to set up redirects?
This past weekend, I made the big decision to move the domain of my primary website from https://emmasax4.info to https://emmasax.com. The main reason I wanted to do this was simply because I actually liked the idea of a .com domain. What I read online was that a .com domain is oftentimes the default, it’s what people tend to remember most, etc. The reason I originally purchased a .info domain was because I’m not a commercial business. I’m not trying to sell anything. But .info stands for “information”, which I later learned was originally designated for information about a famous person, place, thing, or concept. Although I am a person, it just didn’t feel right. But somehow, one year into the revamping of this site and my “branding”, emmasax.com just felt right. Whether any of this is true or not may be a debate on the internet for a while, but I figured, my website, my domain, my decision 💪🏼.
Anyway, my domain isn’t what this blog post is supposed to be about. It’s supposed to be about the actual switch 🔁. So, there were several core things I realized I needed to do immediately to actually switch out the domains.
To summarize, these are the basic steps I used to change the domain on my static site with GitHub Pages:
- Rename the source code repository
- Update where the project name is hard-coded
- Change domain through GitHub Pages settings (or by merging the changes to the
CNAMEfile) and set up SSL certificates for the new domain if needed - Create redirects from old domain to new domain through the use of a new GitHub Pages project
- Set up SEO trackers to monitor new domain
- Wait a several months and monitor traffic to old domain as you go
- (OPTIONAL) Turn off redirects
- (OPTIONAL) Release (or retire) old domain
1. Rename the source code repository
Firstly, I needed to rename my repository (the repository that my core source code is in). Doing this was actually pretty straightforward. I used a selective find/replace, made the pull request, merged, and then changed the name in the settings of the repository 🙌🏼.
2. Update where the project name is hard-coded
Secondly, I needed to actually change the website. This was a bit longer. I had to find/replace a bunch of places in the code, including in blog posts where I had hard-coded the website name (most likely as a code block). The other big things I had to do in this pull request was change the Google/Yandex tokens for my SEO crawlers (I had to add a “new” site to Google, Yandex, and Bing in order to have those search engines track the new domain)—more on this later. I had to update the CNAME file as well, which is what would eventually tell GitHub Pages to do the full domain switch—this became the third 3️⃣ item.
Lastly, I removed a bunch of old blog post redirects (learn more about those redirects I set up in Time Zones, UTC, and Javascript… Oh My!). Although it’d be nice if all of those continued redirecting nicely, I realized it wasn’t a priority anymore. What was a higher priority was making https://emmasax4.info redirect to https://emmasax.com. This leads into the next item.
3. Update the domain in GitHub Pages settings
This step could be done before or after Step 4, but it is simply changing the domain that GitHub Pages is serving your website under. If your static site isn’t served through GitHub Pages, you may need to find another setting to change so that the system knows your site should be served on a different domain.
4. Change redirects from the old domain to the new domain
Fourth, I needed to make redirects from the old site to the new site. And here is where I also learned that with a static site, there’s no super-easy way to make awesome redirects 😿.
The tool that I use to set up my DNS has an easy way to set up redirects. They’re functional, and so that’s great. But, I wanted my redirects to be fancier. If somebody types in https://emmasax4.info, they should be redirected to https://emmasax.com. But what if they pass in something like this: https://emmasax4.info/interests-and-hobbies/theatre/? They should be redirected to https://emmasax.com/interests-and-hobbies/theatre/. And my DNS provider wasn’t capable of providing that service (transferring URL path when redirecting). So, I looked for simple, free, easy-to-implement alternatives that could redirect all URLs 🤔.
What I found was a solution to permanently redirect GitHub Pages from Oleksii Tsvietnov. The idea is to make a new GitHub repository that will publish to GitHub Pages with the old domain. And then, create an index.html file which will redirect to the new domain. So, when a user navigates to the old domain, they’ll hit the new GitHub Pages with your new index.html, and then it’ll redirect automatically to the new domain (which is hosted on the original GitHub Pages repository) 🤯.
I created a new repository to put my new redirects in. I started by taking a modified version of the HTML code in that blog post, which looked something like this:
<!DOCTYPE html>
<html lang="en-US">
<meta charset="utf-8">
<title>Redirecting…</title>
<link rel="canonical" href="https://destination-domain.com">
<script>
location="https://destination-domain.com"
</script>
<meta http-equiv="refresh" content="0; url=https://destination-domain.com">
<meta name="robots" content="noindex">
<h1>Redirecting…</h1>
<a href="https://destination-domain.com">Click here if you are not redirected.</a>
</html>
This worked. I duplicated each index.html file on the original site into this new project, replicating the files found on my pages branch. But I realized this wasn’t sustainable. I didn’t want to be copy-pasting HTML from each file to another all over the place. I wanted one HTML file that would properly redirect any incoming path to the new domain, and forwarding the same path, without me having to make constant updates to the new redirect repository.
Furthermore, I wanted users to know I was redirecting them. I didn’t want to do it under the hood, with them potentially not even noticing they were redirected. I wanted them to have a clear message they were being redirected, and for them to know that they were redirecting to a reputable new site. I wanted the redirect page to look like my existing website, so it was clear they were still within the realm of my original site.
So, the first thing I did was add CSS. I copy-pasted the ./assets/ directory from my main branch to the new repository. I did a selective copy-paste, only copying the CSS, JS, and images that the new “site” required. And then I called those assets straight from my index.html, just like in my core repository. I opted not to include the full navigation bar, but just showing a basic blue top bar, to make it feel like it was still my website.
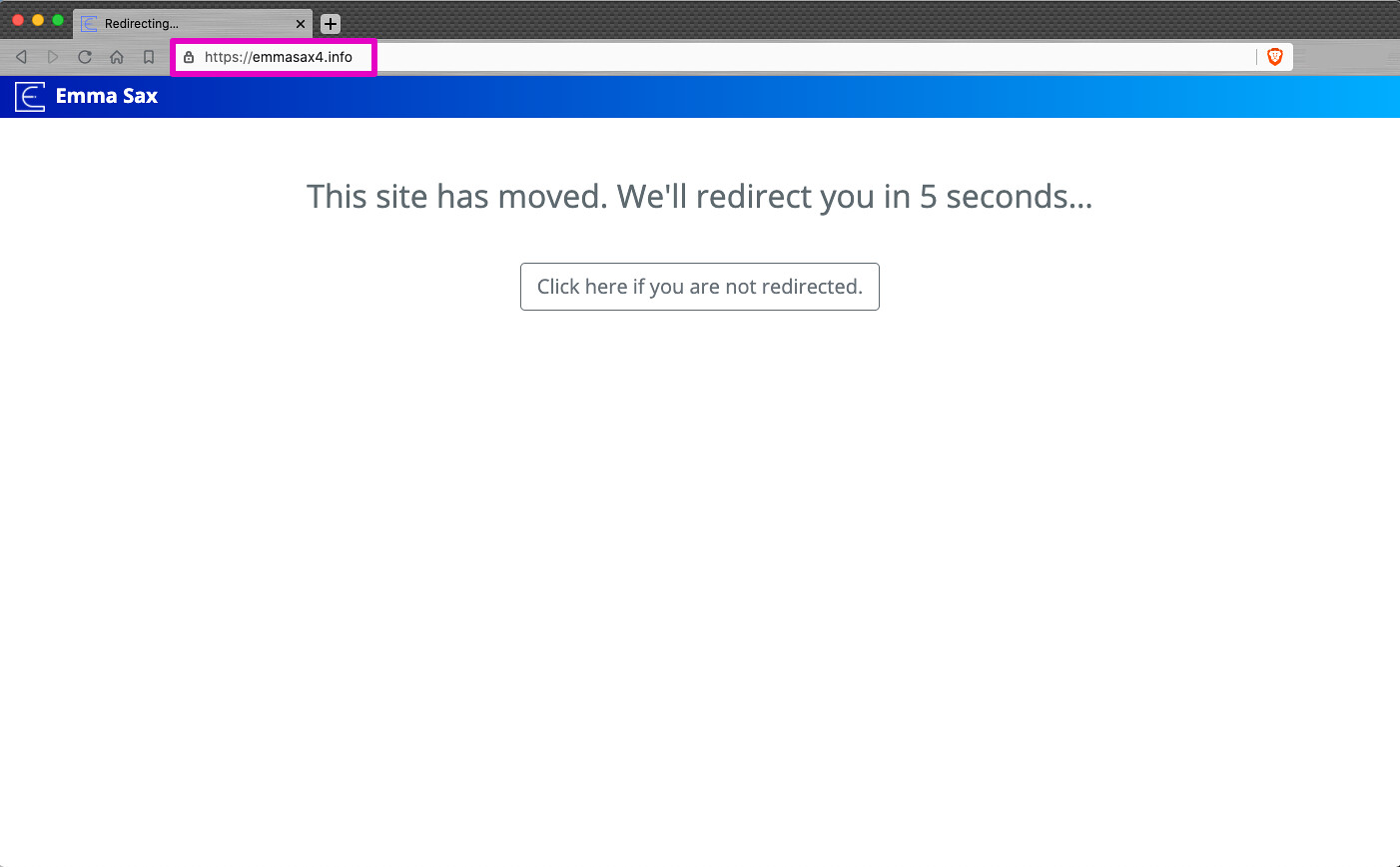
And then the last couple tricks was to add two ways to do the redirect. One was a delayed redirect. So a user would sit on the redirect page for five seconds to be able to comprehend what was happening and then they’d be automatically redirected. The second was for an easy way for the user to redirect themselves. This eventually turned into a button. The tricky part of both of these was forwarding the incoming path. It turns out, the easiest way to do this is to actually use Javascript instead of HTML, like the original blog post suggests. For example, this is how you could read the incoming path that is navigated to, and pass it on in a delayed redirect:
pathname = window.location.pathname;
setTimeout(function(){ window.location.href = "https://destination-domain.com" + pathname;}, 5000);
Now, with this Javascript, the key was to use it in two places: the button, and the delay. This was the ending solution:
<script type="text/javascript">
var pathname = window.location.pathname;
// Perform an automatic timed redirect
setTimeout(function(){ window.location.href = "https://destination-domain.com" + pathname;}, 5000);
// Add button click functionality as well
function redirect_now() {
window.location.href = "https://destination-domain.com" + pathname;
};
</script>
<button class="btn btn-lg btn-outline-secondary" onclick="redirect_now(); return false;">
Click here if you are not redirected.
</button>
Bam! Now, no matter what path a user passes in after the /, they’ll be forwarded to the exact same URL with just a different domain 🥳. The last part of this project was to remove all of the extra index.html files. All we really need are the root index.html to catch when someone navigates to https://emmasax4.info directly, and a page to catch when somebody navigates to…. anything else (https://emmasax4.info/anything/else/goes/here). In that case, we can just make a 404.html file. If the user navigates to anything else besides the plain root, then GitHub Pages will show the 404.html page. And if the 404.html functionality redirects to the new domain, while passing the end of the path (/anything/else/goes/here), then the 404.html page acts as a catch-all. So, I created a symlinked file off of the index.html page:
ln -s index.html 404.html
This way, if I change one of the HTML files, it’ll automatically change the other one. This is what my final HTML file looks like.
5. Set up SEO trackers to monitor the new domain
The fifth step for me to do in the “soonish” future was to update my SEO trackers, indexers, and crawlers. I previously used Google Search Console, Bing, and Yandex to do my SEO tracking. In each of those, I had the option to add a new website or domain (https://emmasax.com). And on Google, I also used the feature to do a “Change of Address.” So for Google, I added the new URL prefix site and completed the Change of Address in Google.
6, 7, and 8. Wait, turn off redirects, and retire the old domain
The next steps are to wait a few months. This is easy! Google recommends waiting a minimum of six months. Since I still own my old domain for a while, I’m probably going to keep my redirects alive as long as possible, which in my case will be over a year. I’ll continue to monitor traffic, clicks, and impressions on tools like Cloudflare, Google Search Console, Yandex, and Bing. With any luck, the amount of traffic going towards the old domain will decrease within a few months, and the traffic on the new domain will increase. But after my waiting period is done, then I can turn off my redirects (in my case, turn off GitHub Pages on the redirecting repository), and release or retire my old domain. If I so desire, I could keep the old domain forever and just eternally let it redirect… it’s my choice.